I’m excited to share the latest development in our hockey prediction project. We have now a live version of the app and a detailed demo video available for everyone to explore.
Live App
The hockey prediction app is now live! You can interact with it and explore its features by visiting the following link.
Demo Video
For those who prefer a guided tour of what the app offers, we’ve prepared a demo video. The video walks you through the app’s functionality and showcases its features:
We hope you find the app useful and informative. Your feedback is always welcome, as it helps us improve and make the app even better.
The shots are consistently more frequent around the offensive zone and the goals are higher closer to the goal and steadily decrease, showing that shots taken closer to the net have a higher success rate.
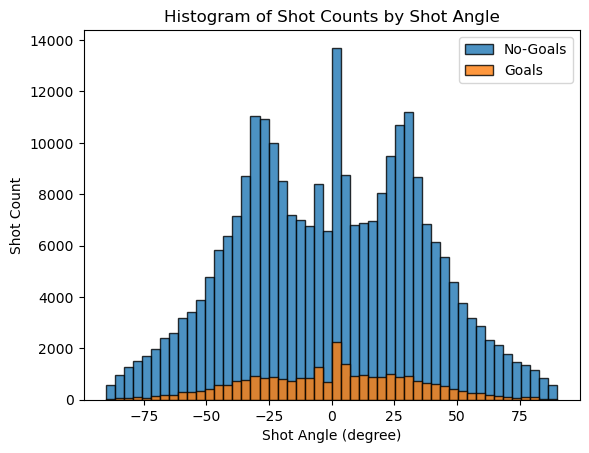
A histogram of shot counts binned by angle
The distribution appears to be symmetric around the 0-degree angle. There are prominent peaks near the center, which correspond to shots taken directly in front of the net. The high number of shots and goals in this area suggests that straight-on shots are more common and successful.
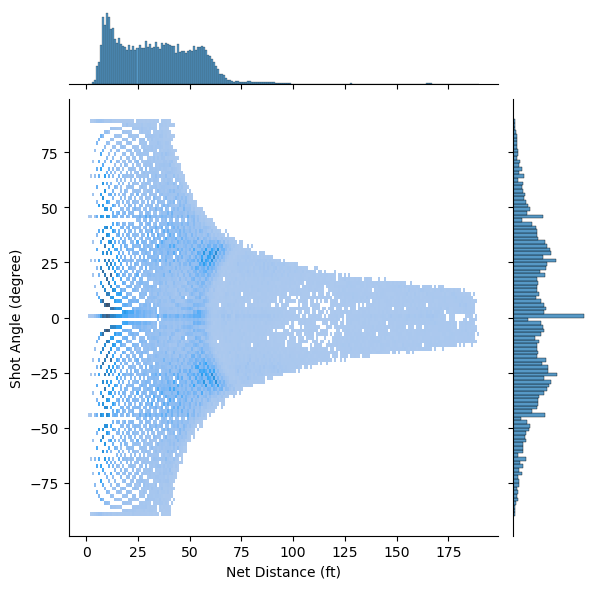
A 2D histogram where one axis is the distance and the other is the angle.
There is a sparse distribution of shots at greater distances, indicating that shots are less frequently taken from far away. As the distance from the net increases, the spread of angles from which shots are taken appears to decrease. This suggests that long-distance shots are less likely to be taken from wide angles.
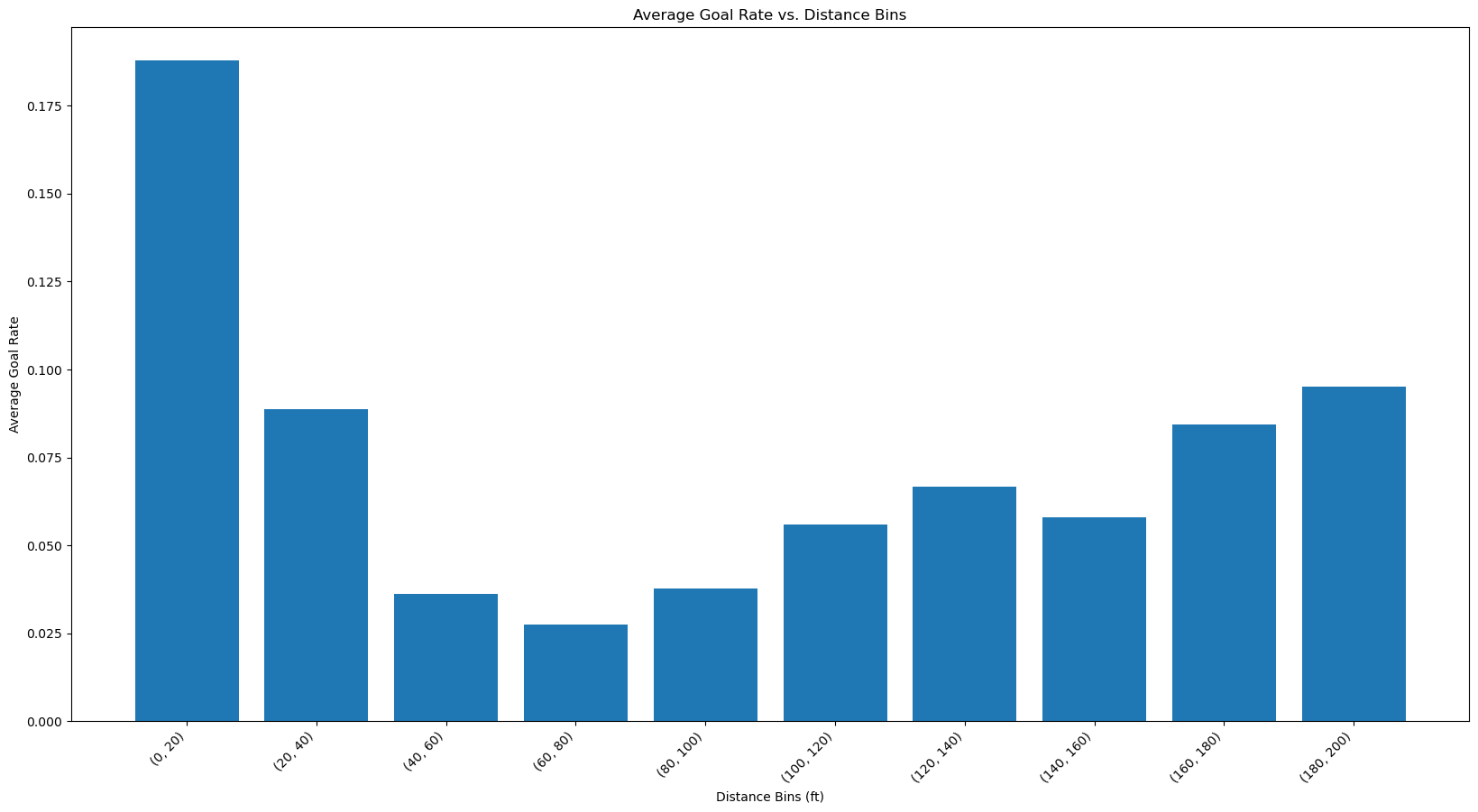
A histogram of average goal rate vs distance bins
Now we have calculated the goal rate which is the efficiency of goal scoring attempts. As seen from the bar plot we can see that the efficiency is more at the distance [0-20] since it’s near the goal post. The interesting thing is that the efficiency increases at higher distances. Even though there were less shots in higher distance, the efficiency of scoring a goal is better than distances in the middle. Since this is counter-intuitive, it might be a sign that there was some mistake either in data processing or in the entry of data and these shots were actually taken from the offensive zone and simply mislabelled which would render our distance calculation wrong.
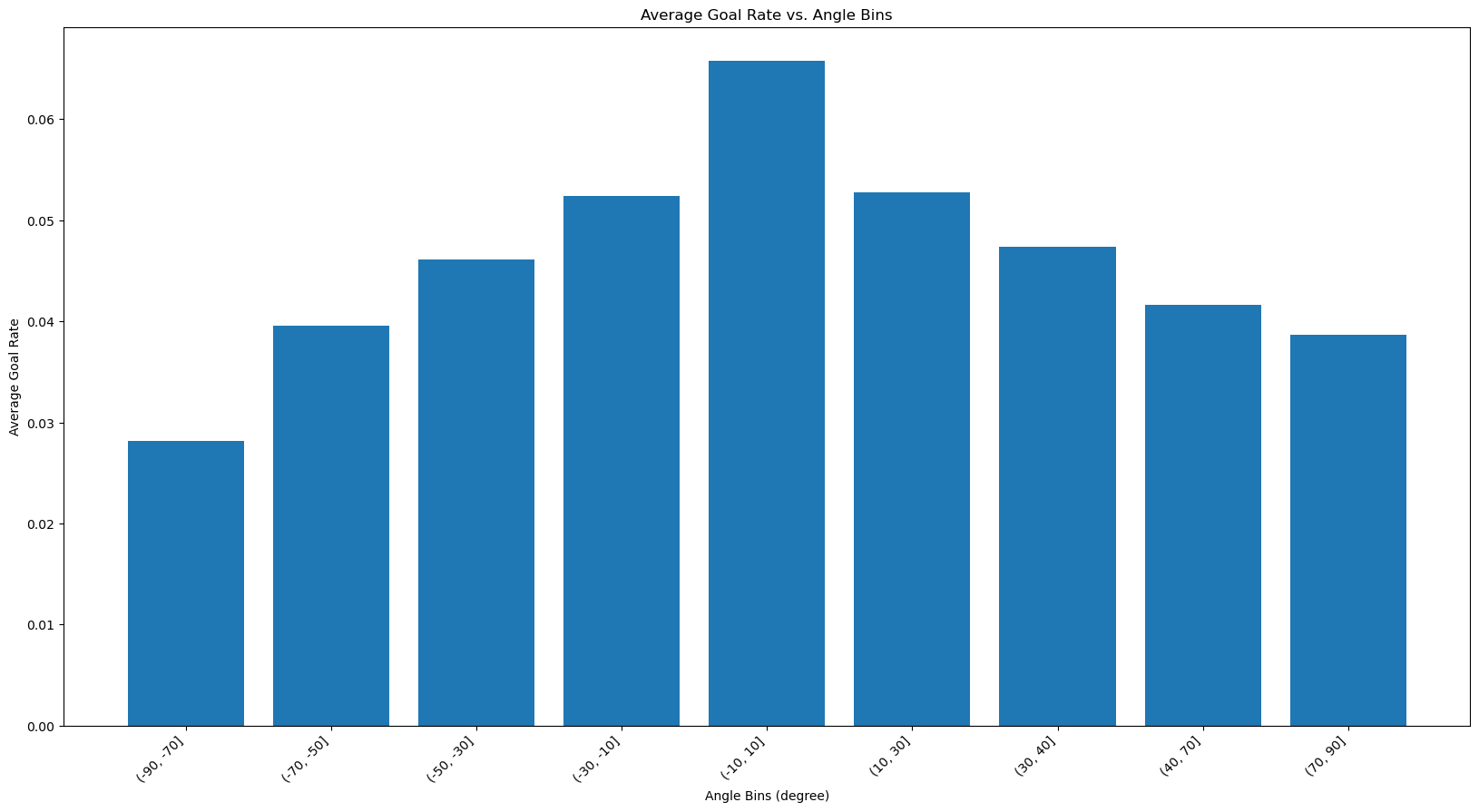
A histogram of average goal rate vs angle bins
The goal rate seems to follow a similar trend that of the shot counts with the highest being directly in front of the goal and then it gets lower as the angle becomes more extreme. As discussed the straight-on shots lead to a higer goal rate.
A histogram of goals count binned by distance.
The majority of goals are scored from a close distance. There are very few goals scored on an empty net. They are spread out over a range of distances, including some from very long ranges. The non-empty net goals are rarely scored from distances beyond 75 feet, underscoring the difficulty of scoring long-range goals with the presence of a goalie.
Regarding the domain knowledge: “it is incredibly rare to score a non-empty net goal on the opposing team from within your defensive zone”, a histogram of goals from team’s defensive zone is created as below.
The histogram reveals that scoring a non-empty-net goal on the opposing team from the team’s defensive zone is indeed a rare event. The distribution suggests that these occurrences are relatively random and are not heavily influenced by the distance from the goal. Additionally, it’s noted that some goal data may be recorded incorrectly, with one example is the first goal of game 2018020722 at 04:39, 1st period. The x/y coordinates have been recorded incorrectly to -85 and -22 respectively. For verification and context, game highlights are available through the provided link. This could explain why for certain bin distances, there are even more goals with a non-empty net than with an empty net.
3. BaseLine Models
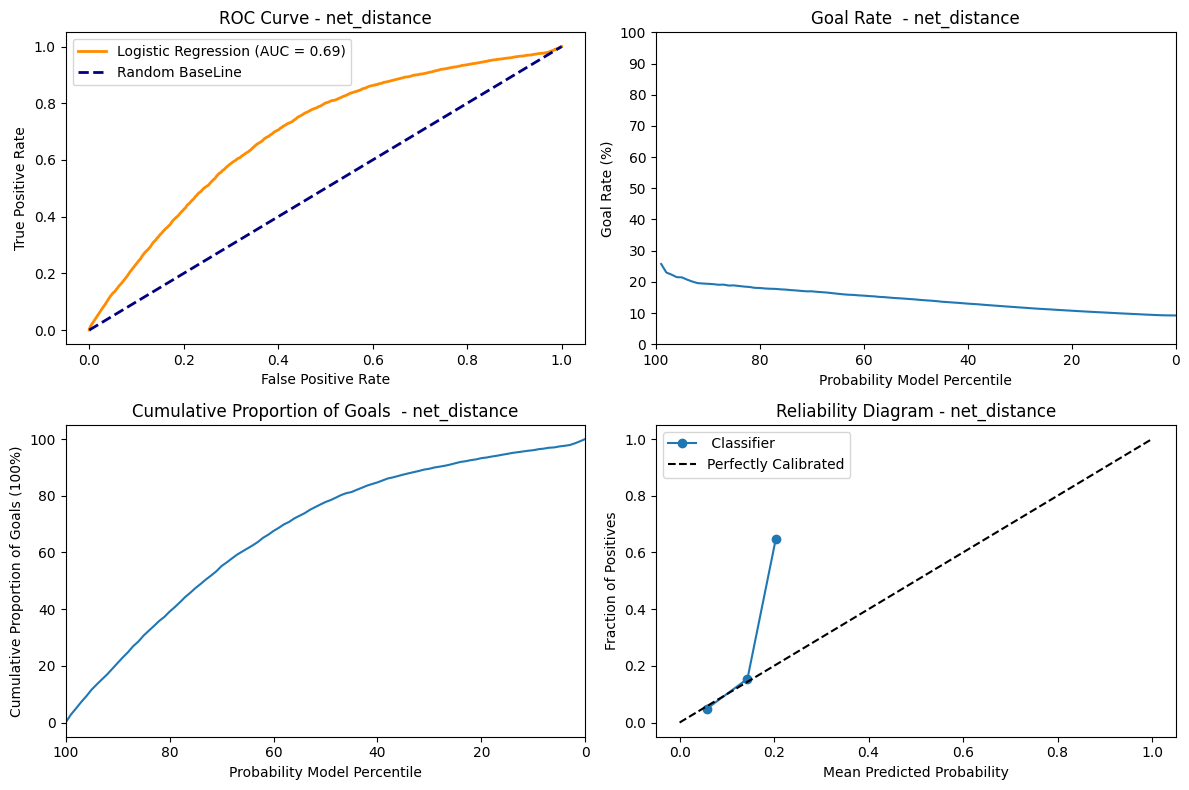
We created a training and validation split and used net_distance from out train dataset to predict binary classification of is_goal in our dataset and calculated the accuracy. The accuracy we were getting was 0.90 which is a good one. But then after looking at the predictions we noticed that most of the values were 0. When we used y_pred.sum(), the result was 0. This lead to the conclusion that the data is imbalanced and the class 0 is overrepresented which leads to a very accurate model. In hockey, it’s common knowledge that goals are rarely scored, hence class 0 represents the amount of goals that were missed. Another metric like recall would show that our classifier’s performance is overestimated with accuracy alone.
ROC Curve: The AUC metrics = 0.69 shows that the model is able to discriminate between the positive and negative instances moderately.
Goal Rate: This graph shows a decreasing trend which shows that at the percentile decreases the goal rate also decreases. Therefore at the highest predicted probability the goal rate is at it’s max. That descent is not very step on the other hand and we can see that whether the model is confident in its prediction or not, the goal rate does not vary that much, which shows its not very discriminating.
Cummulative Proportion of goal: This graph shows that for the highest probability, the curves is the most steep. As such, the highest proportion of goals is scored when the model is very sure. As the probability decrease, the cumulative number of goals increase, but at a smaller and smaller rate.
Reliability Diagram: The line follows the “Perfectly Calibrated” untill 0.2 and deviates from it and jumps to 0.7. This might indicate that the model predicted probability is only reliable untill 0.2. We also see that the prediction curve stops very early, which shows that our model is not able to generate probabilities higher than a bit over 20%.
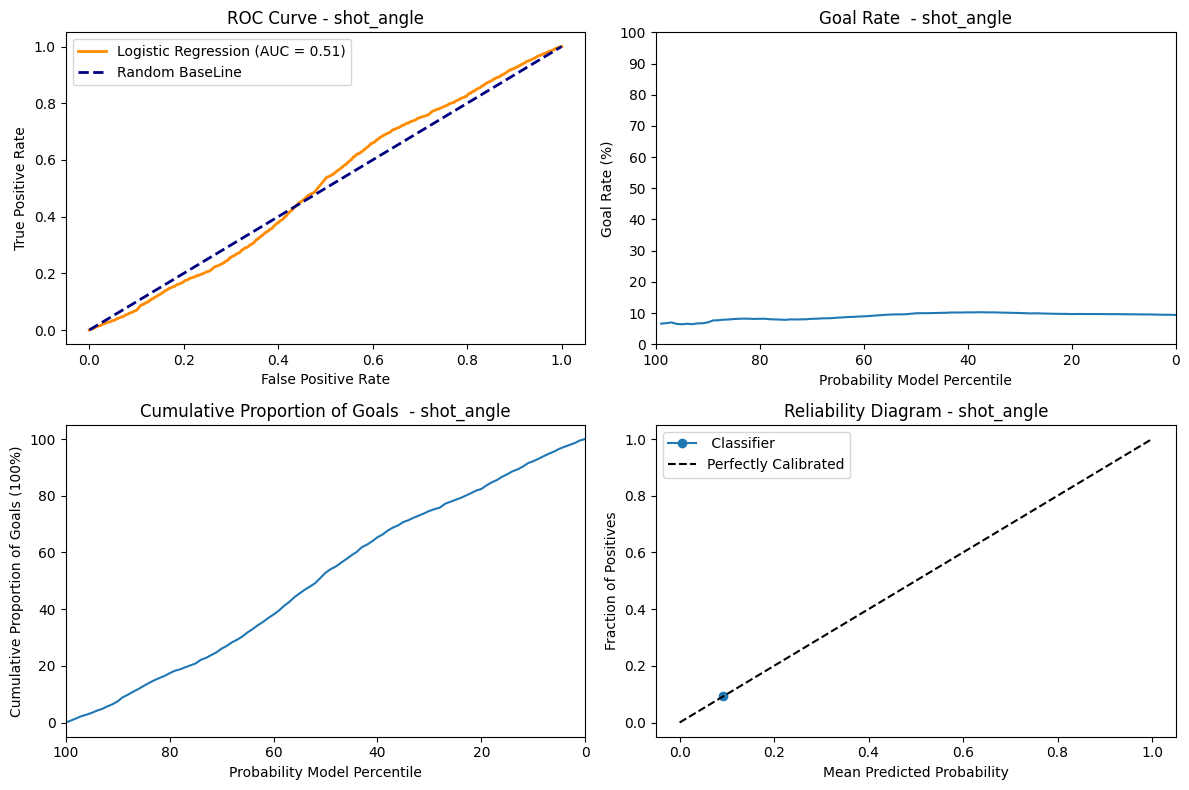
ROC Curve: The AUC metrics = 0.51 indicates that the model is pretty much a random classifier, which has a fifty-fifty chance of guessing the right class.
Goal Rate: Since the AUC = 0.51 the model is not able to assign high goal rate to highest predicted probability. The goal rate is 5% at percentile 0 and also 5% at 100 percentile and almost remains close to constant of 5% at every percentile. This uniform distribution shows that the prediction of the models has no effect on the goal rate.
Cummulative Proportion of goal: Since the model is not able to discriminate properly, the cumulative goals shows an almost completely linear and regular ascend as the model probability decreases.
Reliability Diagram: Having only one dot on the “Perfectly Calibrated” tells us that the model does not give us additionnal information. So the angle feature alone is not enough to predict the probability of being a goal or not.
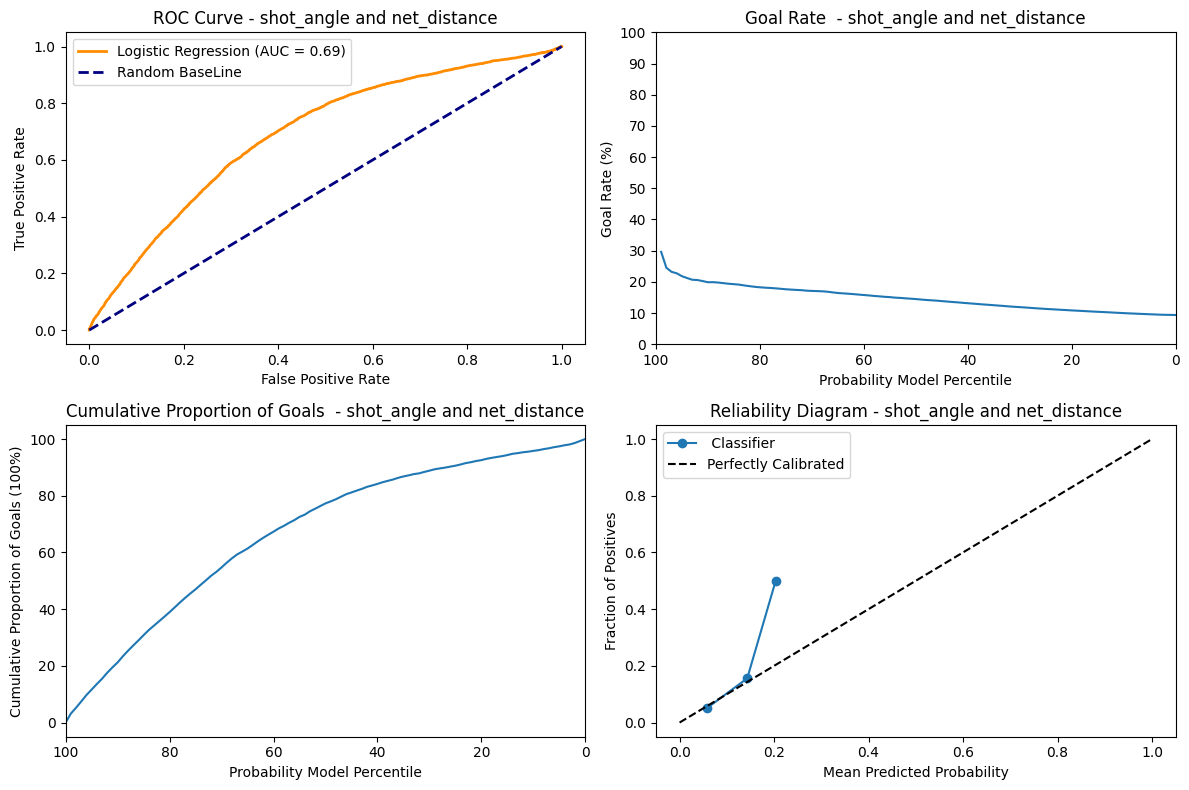
Logistic Regression Trained on net_distance and shot_angle.
As seen from the net_distance the AUC score, goal rate , accumulation of goals and reliability diagram are all similar except the goal rate for this graph starts from 30% and shows a slightly steeper descent. This shows that the shot_angle, even when combined with the net_distance does not perform that much better than net_distance alone using a logistic regression classifier.
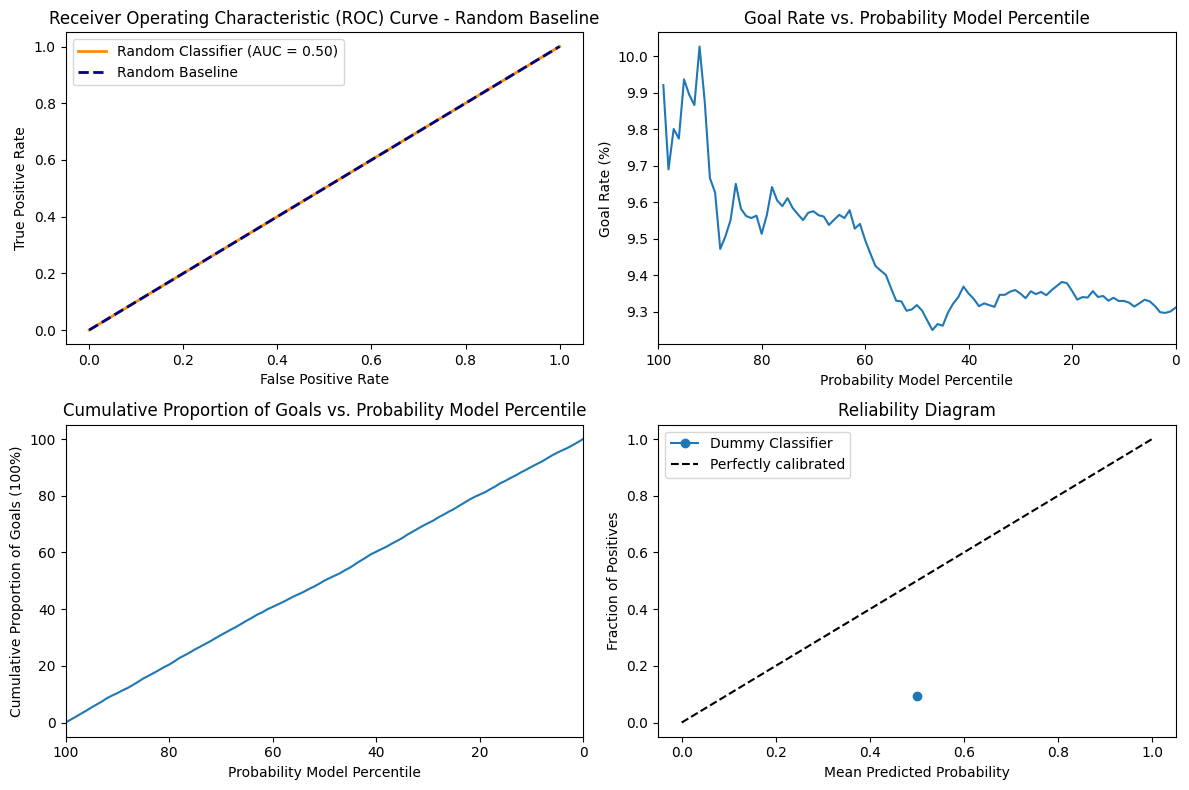
The AUC score is 0.50 since the model does not have any discriminative power. We can also see that the goal rate is very stationary at the around 9.3 to 10 for all values of percentile. The Accumulation of goal has a very uniform increase and decrease in accumulation of goal and percentile. Since the model is random it is not calibrated at all and simply varies according to chance and our particular distribution.
4. Feature engineering II
In the dataset we’re working with, each feature provides unique and insightful data regarding the events of NHL games. Here is a breakdown of each feature:
game_id: The unique identifier for each game.
event: Type of event being recorded, such as a ‘SHOT’ or ‘GOAL’.
prev_event: The event that immediately precedes the current event.
period: The period of the game in which the event occurred (1, 2, 3 for regular time, additional for overtime).
date_time: The real-world date and time at which the event happened.
period_time: The time on the game clock when the event occurred.
game_seconds: Total number of seconds elapsed in the game when the event occurred.
time_from_pre_event: The time elapsed since the previous event.
prev_team: The team that made the previous event.
team: The team that is associated with the current event.
x_coordinate: The x-coordinate on the rink where the event occurred.
y_coordinate: The y-coordinate on the rink where the event occurred.
prev_x_coordinate: The x-coordinate of the previous event.
prev_y_coordinate: The y-coordinate of the previous event.
shooter_name: The name of the player who took the shot.
goalie_name: The name of the goalie involved in the event.
shot_type: The type of shot taken (e.g., slap shot, wrist shot).
empty_net: Indicates whether the goal was empty when the shot was taken.
strength: The strength of the team during the event (e.g., even strength, power play).
power_play_elapsed_time: This feature tracks the time elapsed during a team’s power play. It resets to zero once the power play ends.
friendly_non_goalie_skater: This feature counts the number of skaters, excluding goalies, for the team currently in control of the puck.
opposing_non_goalie_skater: This feature tallies the number of skaters, excluding goalies, for the team without the puck.
attacking_side: The side of the rink is being targeted in the event.
net_x: The x-coordinate of the net being targeted.
net_distance: The distance of the shooter from the net when the shot was taken.
distance_from_prev_distance: The change in distance from the previous event to the current event.
shot_angle: The angle of the shot relative to the net.
is_goal: Indicates whether the shot resulted in a goal (1 for yes, 0 for no).
is_empty_net: Indicates whether the net was empty when the goal was scored.
is_rebound: Indicates whether the shot was a rebound.
change_in_shot_angle: The change in the shot angle from the previous shot.
speed_of_change: Defined as the distance from the previous event, divided by the time since the previous event.
Each of these features will help us to analyze the game with greater precision and insight.
This is the link to the experiment storing a filtered dataframe for game 2017021065.
5. Advanced Models
Baseline XGBoost classifier
For this step, I used a training, validation split of 80/20. Since we have a large training set, this seemed like a good split to ensure there is sufficient data in both the training (for proper fitting) and validatidation set (so the metrics calculated are representative).
I used a preprocessing function to generate the split even though the features were very simple, because I was going to reuse it for later questions and it made the codebase cleaner.
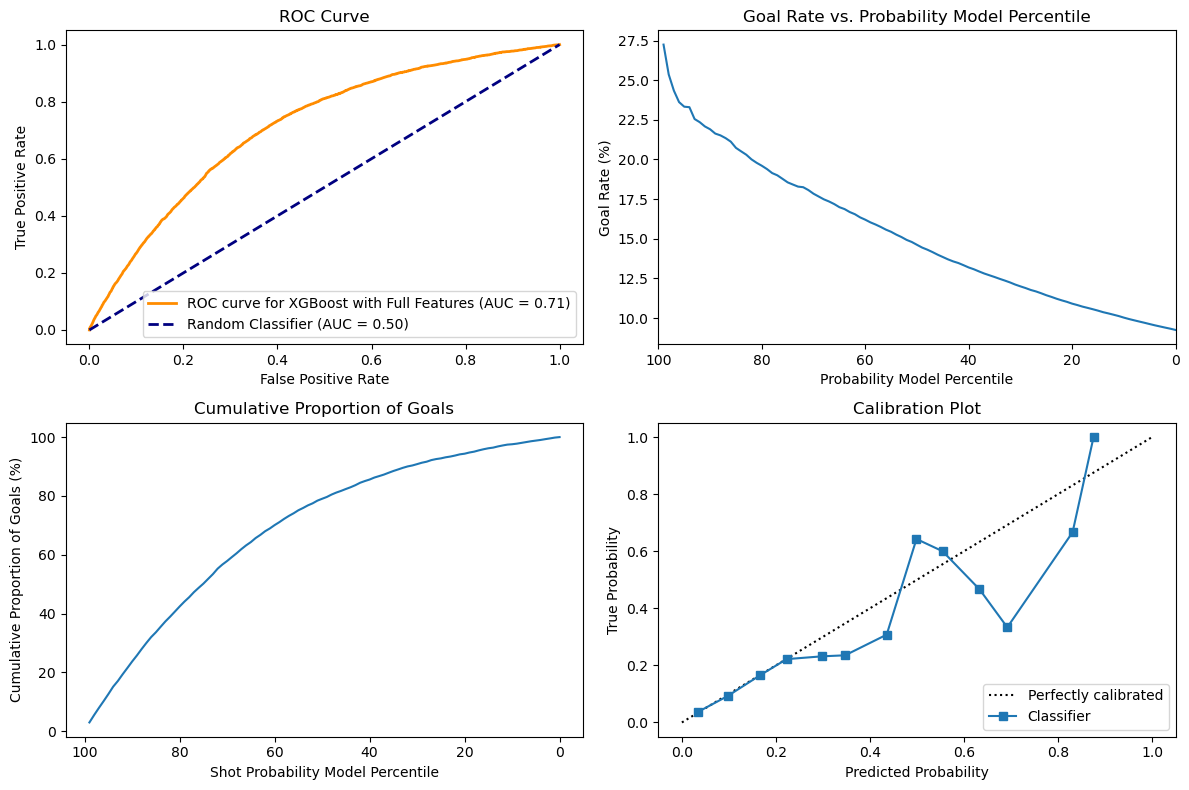
Just using two features, it looks like the XGBoost model performs slightly better than the LogisticRegression classifier, but the difference is very slim.
Looking at the first subplot, there is a marginal increase of the ROC from 0.7 to 0.71, thus showing that the model performs slightly better at correctly predicting goals. XGBoost are based on decision forests, but are boosted models with more capacity than Logistic regression, which might explain this difference. The difference will probably be higher as we get more features, because tree-based models are better at dealing with large dimension spaces.
The second and third subplots do not really show an obvious difference between the two classifiers and just looking at the curves do not show a significant difference in the ability of both classifiers to predict goal rate and cumulative goals.
Finally, looking at the calibration plots, we can see that both classifiers perform well until around 0.2 of predicted probability, but higher than that they start to diverge from the calibration plot. In the case of the XGB, the variance does not seem skewed and it both underestimate and overestimate the true probability, since there are points on both sides of the calibration line.
For hyperparameter tuning, I decided to use an automatic optimization method to find the best hyperparameters. Since we are interested in the probability of goals and not only the actual prediction, I used log_loss as my metric for optimization since it relates more to probability.
I already had experience working with Optuna, which is a library to perform automatic optimization using a bayesian approach, which helps the model converge faster than simply using GridSearch and gives better results than RandomSearch from my experience. Since we had to work with comet.ml, I decided to use their own optimization library so I could log my experiment more easily and generate figures related to the optimization process. This type of library necessitates to have a dictionary of parameters, so I used a list from the official Optuna github with all the usual parameters for an XGBoost classifier.
Link to dictionary : https://github.com/optuna/optuna-examples/blob/main/xgboost/xgboost_simple.py
This approach had the advantage of being exhaustive and not necessitating too much knowledge about each hyperparameter.
The XGBoost model has a lot of hyperparameters and choosing the best option is complex, because the choice of one hyperparameter influences the others. For instance, both alpha and lambda are a form of regularization, so if one of them is already high, the other can be lower and vice-versa. If the model is properly regularized, we can train for a long time without overfitting, but if the regularization parameters are low, the model might overfit with a large number of epochs.
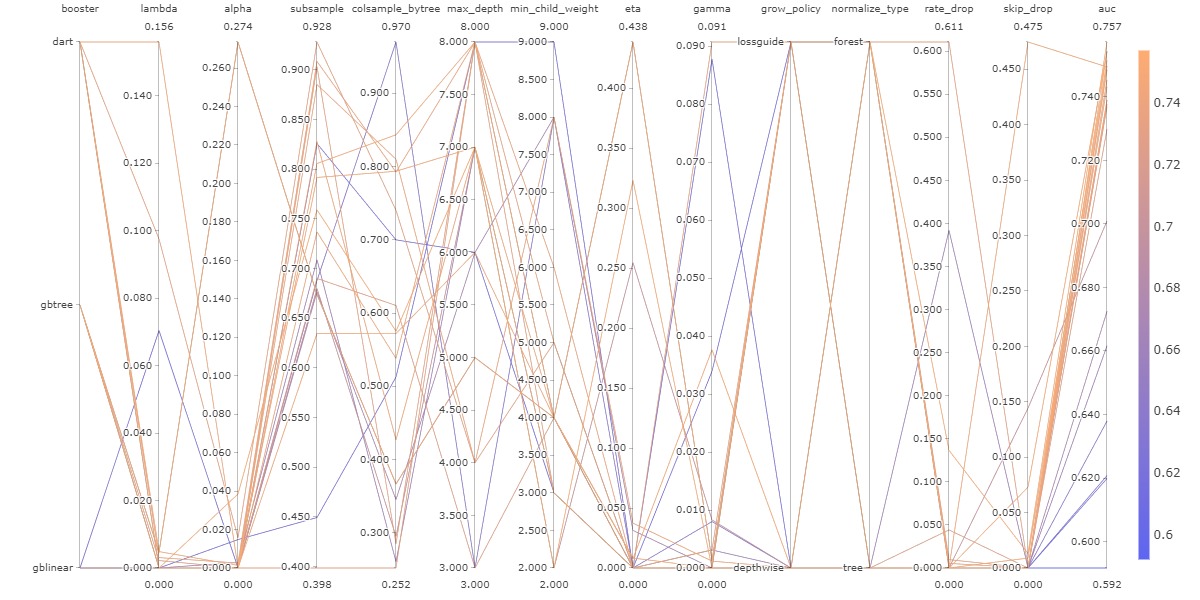
The following figure shows all the different combinations used during this optimization. The figure is complex and hard to interpret, but its simply here to show that modifying one hyperparameter at a time is not enough, since we can see that every line zigzags up and down and even though one hyperparameter choice might seem like it lowers the accuracy, when combined with another hyperparameter it ends up being an advantageous choice.
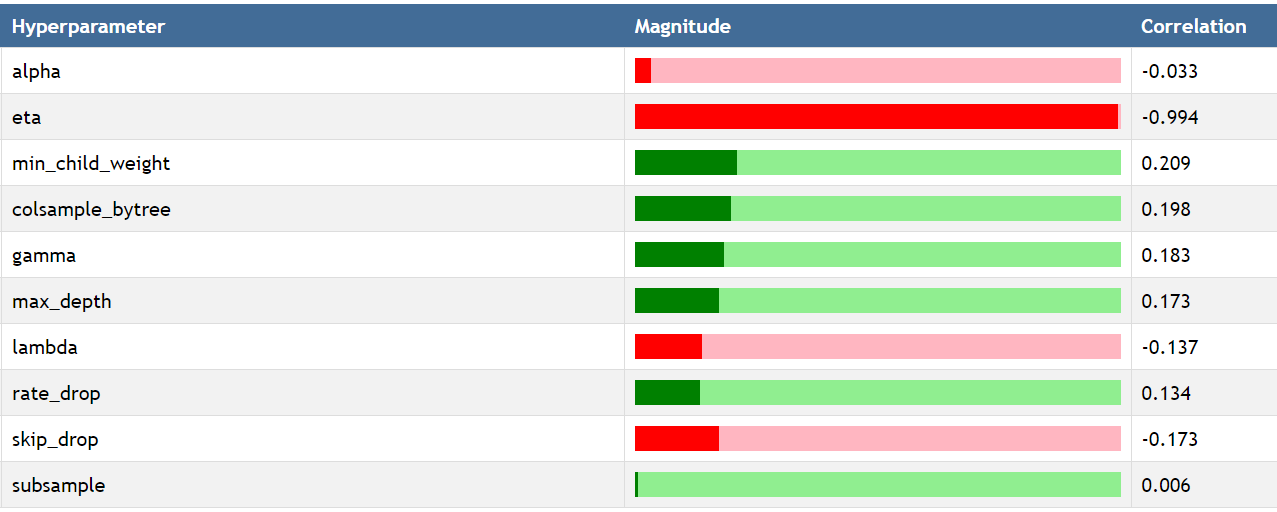
The following figure was created by using a custom report available on comet.ml to see the impact of each hyperparameter on the log_loss metric by using Spearman correlation. The most important hyperparameter is eta which corresponds to the learning rate. This make sense intuitively, because if the learning rate is too high, the model will never converge and instead jump back and forth.
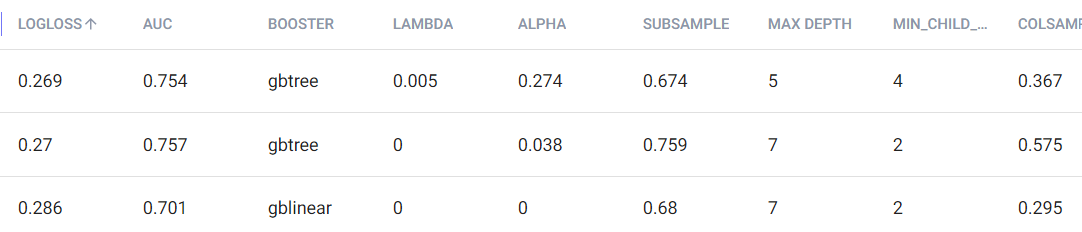
Finally, to further prove how complex hyperparameter tuning would be without using an agnostic approach like hyperparameter optimization, we can see below some of the hyperparameters for the 3 experiments with the lowest logloss. Even though their logloss is very similar, they all have various combinations of hyperparameter that sometimes vary widely.
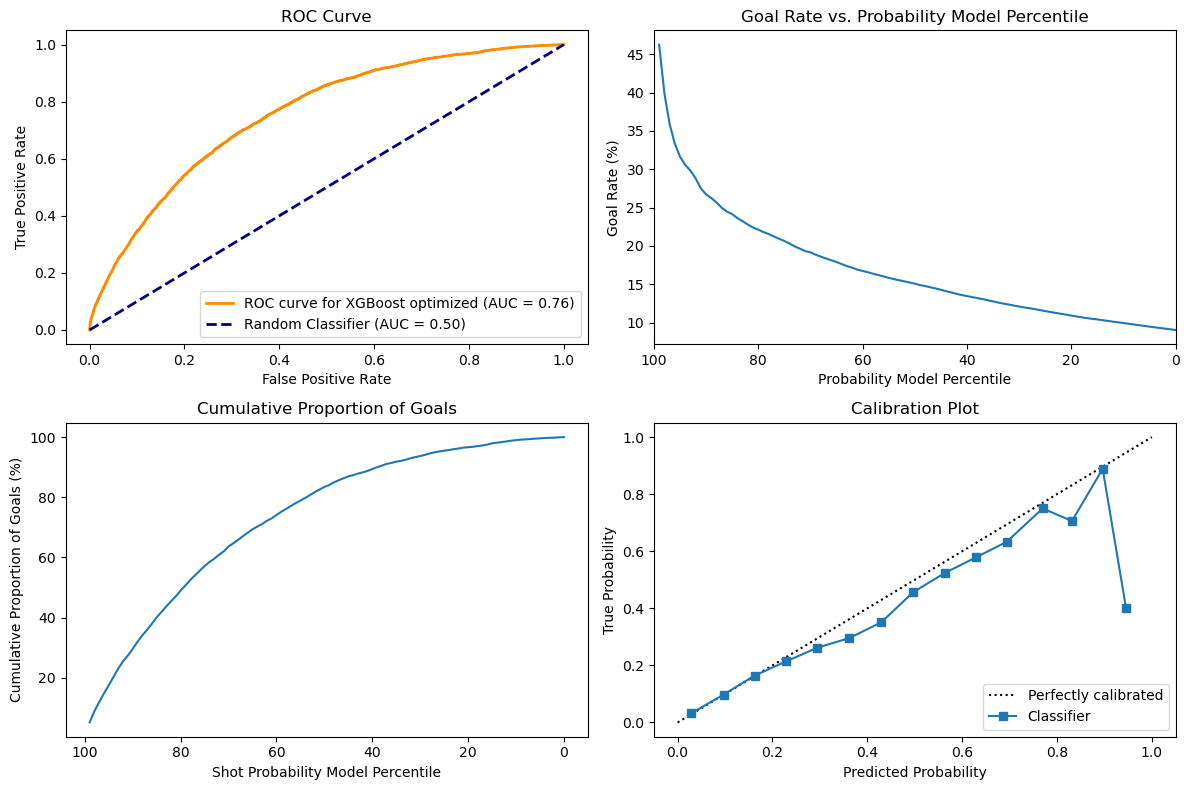
With the hyperparameter optimization, the model was able to improve significantly. Comparing the model with the baseline, we can see below that its performance as a classifier has improved significantly, with the AUC now being 76% as compared to 71% on baseline. Looking at the Goal rate, we can see that when the probability model percentile is very high it is now associated with a much higher goal rate with the line going a bit over 45 as compared with 27.5 around the 99th percentile. This shows that the model is better at detecting high probabilities and that is also reflected in the calibration plot. The cumulative proportion of goals still has a very similar curve that is hard to distinguish between models.
Feature selection
For feature selection, I decided to use a sequential approach by using progressively more complex techniques. There are some automated feature selection tools available with the sci-kit learn library that can choose feature either based on their importance or on their impact on a predefined metric. To do so they can test sequential removal or adding of features and see how it affects the intended metric. Having used Recursive Feature Elimination with Cross Validation in the past, I knew that the runtime would be very long if I did not try to at least remove some features before.
I first looked at highly correlated features, using an arbitrary threshold of 0.80. Highly correlated features do not add more information in combination than any of them alone and they tend to make models, especially linear ones unstable. With that, I was able to remove two features.
After that, I looked into feature selection by feature importance. To do so, I made sure to add a standard scaler in my preprocessing steps, even though it is not a necessary steps in the training of an XGBoost model, to make sure the values were comparable.
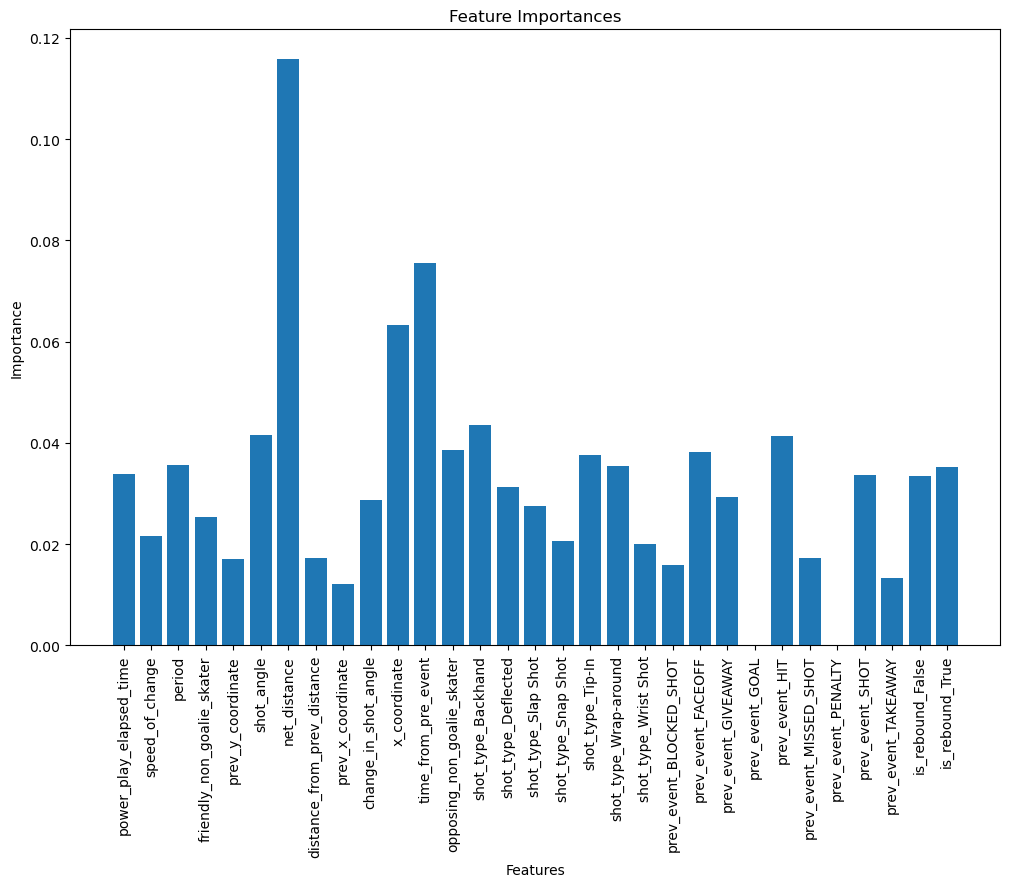
Looking at the graph below, we can see that some features were not used at all in the construction of the XGBoost like prev_event_goal and prev_event_penalty. I guess that after a goal has just been scored, since the plays are restarted it does not correlate with the chances of having another goal. Interestingly, the most important feature is one we calculated in the first part, net_distance which is very intuitive. The time from prev_event too, since if the events are very close, it means the game is very active, there are a lot of passes or shots and a higher chance to score.
With this method, I ended up with around 15 features, which I thought was a big cut from the original features. Since XGBoost perform well even in high dimensionality, I wanted to make sure using another technique based on performance this time that I was not removing too many useful information.
I decided to use sequential feature selection by using a backward approach, to try and ensure to keep as many features as possible. This ended up necessitating a runtime of more than 3 hours on my computer and in the future, we will probably spend more time on manual removal before using this type of method.
Interestingly, even this greedier approach ended up selecting only 16 features out of the 31 (including every onehot encoded categories). A lot of the features were the same and only 6 differed between both sets. I ended up going with the features selected by score, because I thought the small difference still made a difference on the estimator score.
After choosing the final subset of features, I tried to run an hyperparameter optimization again, but looking at cross-validation scores, the original hyperparameters on which feature selection was based performed slightly better, so I ended up keeping that combination of hyperparameter and features.
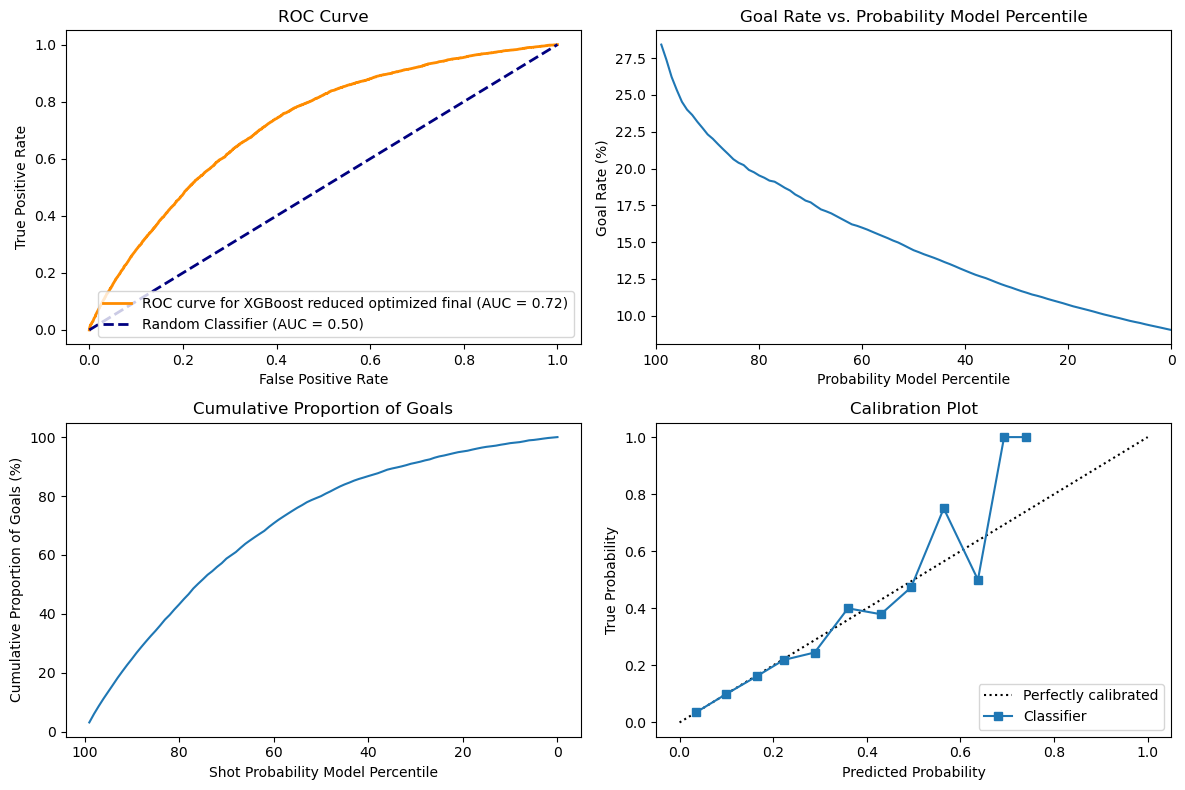
Comparing these results with the baseline XGB, we can first see a small increase in the accuracy as shown in the ROC that is slightly higher with an area under curve of 0.72 instead of 0.71 now. The curves for cumulative goals and goals rate are similar, but the model nows predicts a slightly higher goal rate when it is very confident. I do not see a meaningful difference for the cumulative goals.
Interestingly, without feature selection, the XGBoost model performed very well with an AUC-ROC of 76% and a calibration plot that was almost perfect. The problem might be due to overfitting, but since we used a validation set, it will be interesting to see the results on the test set. Finally, looking at the calibration plot, we can see that the XGBoost is now very precise until around 50% of predicted probability, but after that the model is not able to be confident enough in its prediction, which might be due to loss of relevant informations.
6. Best Shot
In this part of the project, we tried playing with the Feature Engineering part coupled with New Algorithms to see if we can improve the performance of the model.
Various Feature Engineering Techniques and Classification Algorithms
We first used Label Encoders for the Categorical features in this complied with the StandardScaler to scale thing normally. Moreover, instead of removing the whole rows of the Data with some missing values, we tried to populate it with the use of Interpolation. This significantly increased our accuracy on the simplest Classification Alogrithms like Decision Tree and Random Forest. We also tried to use the Sequential Model(Neural Nets) to check if there is any specific advantages.
Here are some Graphs for the Decision Tree, Random Forest and Sequential Model to demonstrate the performance of the model.:
Decision Tree Classifier with Cross ValidationComet
Random Forest Classifier with Cross ValidationComet
We can see the KNN Model performed the worst when compared to other models. The Decision Tree and Random Forest and Sequential Model performed fairly equally but considering the Simplicity of the Decision Tree we chose it to be our best model.
7. Evaluate on test set
Comparison of Models on Regular and Playoff Dataset
Comparision of Models on Regular Dataset
Comparision of Models on Playoff Dataset
As seen from the above graphs most of the models performed similarly to the validation set.
The ROC curve remains consistent for the Regular and Playoff dataset. This shows that the model is able to discriminate between the positive and negative instances normally.
So, conclusively we can say that the models are generalizable well on the test set, since their performance is similar to the validation set and the ROC curve is consistent for both the datasets for each of them. Though a clear exception to the Reliability Curve is the XGBoost model which is not able to predict the probability of the goal properly on the Regular Dataset but does fine on Playoff Dataset.
Surprisingly, even though the Decision Tree classifier performed very well on the training and validation data, it also acted as a near perfect classifier on the test set with around 99% accuracy. We initially wondered if we might have overfit the dataset, but it seems like it simply works very well. Multiple preprocessing steps and iterating through various models and optimization techniques led us to find this very optimal model.
The data acquisition process is one of the most important and initial steps of any data science pipeline. The data acquisition process for this project is as follows:
Data Retrieval: Using the requests library, I will send a GET request to the NHL API to retrieve the data. The API will return a JSON object containing the requested data. The data will then be parsed and stored in a Pandas DataFrame in step 3.
1.1. Data Retrieval
The following code snippet demonstrates the data retrieval process. The function game_id_generator() generates a list of game IDs for a given season. The class DataDownloader() is responsible for retrieving the data for a given game season and stores it in a JSON file.
defgame_id_generator(year:int)->[str]:year=str(year)total_games=(1230ifyear=='2016'else1271)ids=[]# this is the regular season
forjinrange(1,total_games+1):ids.append(year+'02'+'{:04d}'.format(j))# this is the playoffs
foriinrange(1,10):forjinrange(1,10):forkinrange(1,8):ids.append(year+'030'+str(i)+str(j)+str(k))returnids
1.2. Data Storage
The file data_downloader.py contains the class DataDownloader() which is responsible for retrieving the data for a given game season and stores it in a JSON file. The class contains the following key methods:
__init__(self, path: str|None, rewrite: bool = False,threaded:bool=True, worker:int=10, logger_path: str|None = None, log_level: int|None = logging.INFO): The constructor of the class. It takes path to the directory where the data will be stored, a boolean value indicating whether to rewrite the data if it already exists, a boolean value indicating whether to use multithreading, the number of threads to use, the path to the logger file, and the log level. The default values are set to None, False, True, 10, None, and logging.INFO respectively.
download(self, year: int) -> None: This method is responsible for downloading the data for a given year. It takes the year as an argument and returns None.
A major feature of the Downloader class is that it can be used to download the data in parallel. This is achieved by using the threading module.
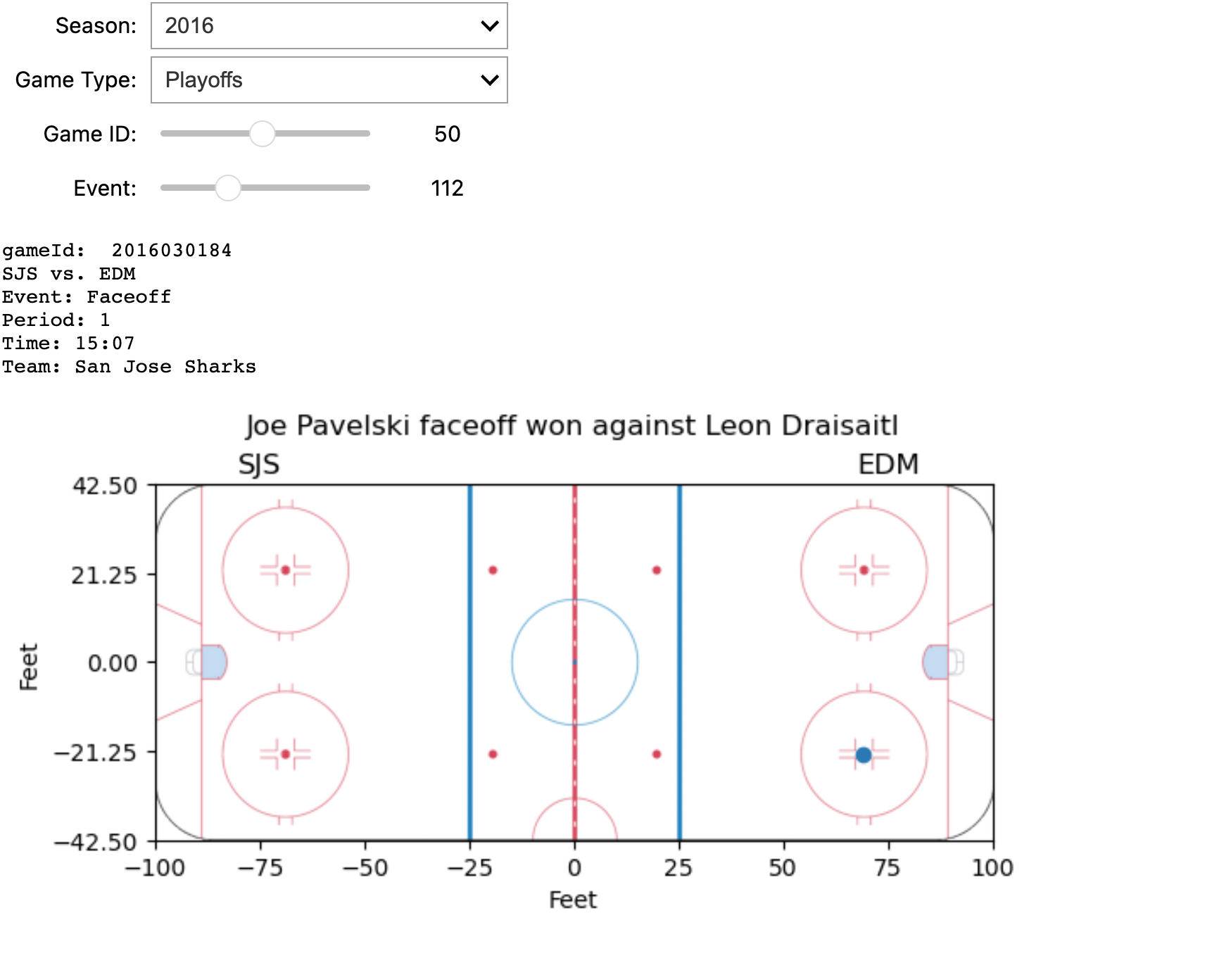
2. Interactive Debugging Tool
The screenshot displays some information about a specific game and an event within it, all of which can be dynamically configured using four interactive widgets. Below is the implementation of the tool.
3.2. Adding the actual strength information to both shots and goal
Assuming penalty events are provided with a start time (X), duration (T), and the penalized team (A), any events occurring within the time frame (X + T) will see team (A) with a reduced player count by at least one, compared to the last event before time (X). This principle also applies to the opposing team. We will maintain a record of the number of players on each team from the start of the game (typically 5-5) until its conclusion. Consequently, we can deduce the on-ice strength during shots and goals within the time frame (X + T) based on the team executing the event.
3.3. Additional features
Real-time performance analysis enables a detailed examination of both team and player behaviors during a game. I will incorporate three metrics for each team, calculated from the start of the game up to each event:
Goals per Shot: Calculated as the number of goals divided by the number of shots, this metric gauges scoring efficiency.
Saves per Shot: Determined by dividing the number of saves made by the number of shots faced, this metric assesses goaltender performance.
Faceoff Win Rate: Calculated as the number of faceoffs won divided by the total number of faceoffs that have occurred, this metric provides insight into a team’s control over puck possession.
4. Simple Visualizations
4.1 Comparing the shot types over all the teams.
df['season']=df.gameId.apply(lambdax:str(x)[0:4])
In order to visualise only the seasons we are interested in, we first filter out all other seasons. In this code, you are essentially creating a new column, ‘season’, in your DataFrame df. The values in this column are derived from the ‘gameId’ column by extracting the first four characters, assuming that these characters represent the season information. For example, if a ‘gameId’ is ‘2017020235’, the corresponding ‘season’ value would be ‘2017’. This operation allows you to easily categorize and analyze your data based on seasons, providing a valuable additional dimension for your analysis.
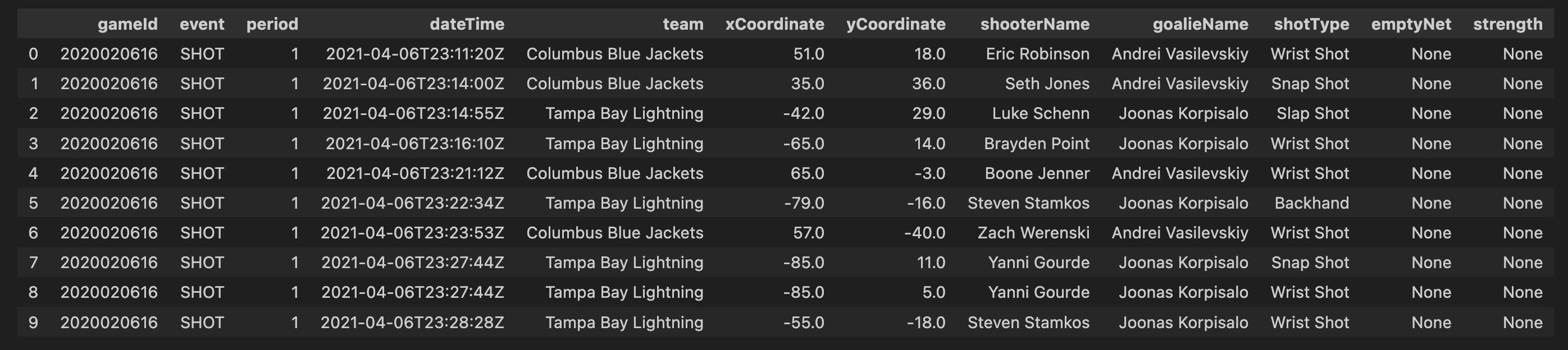
So having done that we just wanna know the distribution of shots and goals in season 2017 just to have a general overview of the graph. We plotted bar graph so that it explains count of all type of events in a more easy way to convey the distribution of shot types across teams in the specified season, enabling your audience to quickly grasp and understand the key insights from the data.
plt.figure(figsize=(11,7))bars=plt.bar(shot_type_for_1_season.index,shot_type_for_1_season.values,color='blue')forbarinbars:yval=bar.get_height()plt.text(bar.get_x()+bar.get_width()/2,yval,round(yval,2),ha='center',va='bottom')plt.xlabel('Shot Types')plt.ylabel('Count')plt.title('Distribution of Shot Types across Teams in season 2017-2018')plt.show()
As seen in the graph, the most common type of shot is the “wrist shot” which has a count value of 46,520.
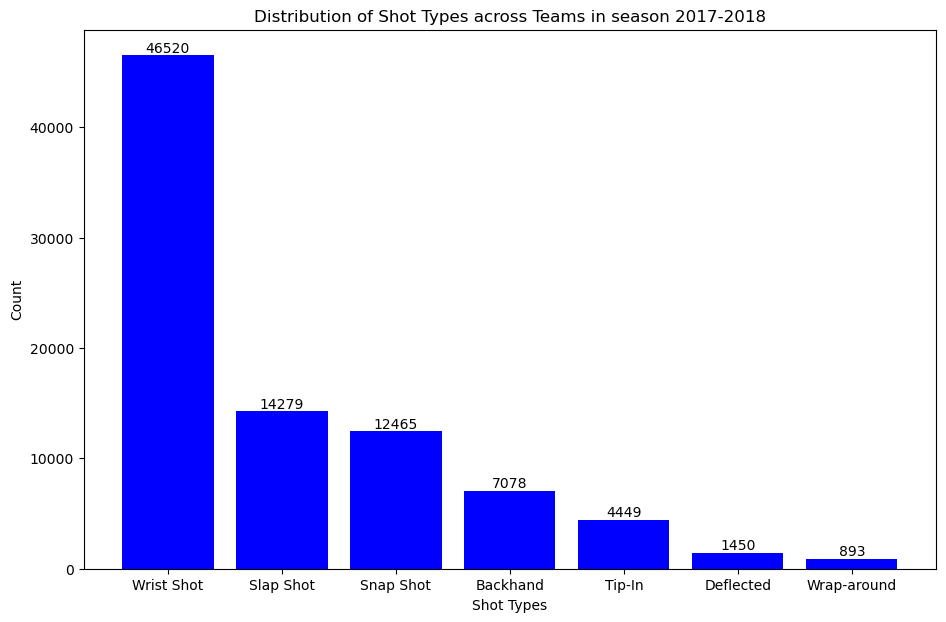
The next step is to analyzing and visualizing these counts could provide a comprehensive overview of team performance in terms of shot selection and goal-scoring proficiency. In our analysis, where we’ll explore visual representations and delve deeper into the significance of these shot and goal distributions.
plt.figure(figsize=(11,7))bars1=plt.bar(shot_counts.index,shot_counts.values,color='orange')forbarinbars1:yval=bar.get_height()plt.text(bar.get_x()+bar.get_width()/2,yval,round(yval,2),ha='center',va='bottom')plt.xlabel('Shot Types')plt.ylabel('Count')plt.title('Distribution of missed Shots in season 2017-2018')plt.show()
This plot gives us the distribution of missed shots accross all the teams in season 2017-2018
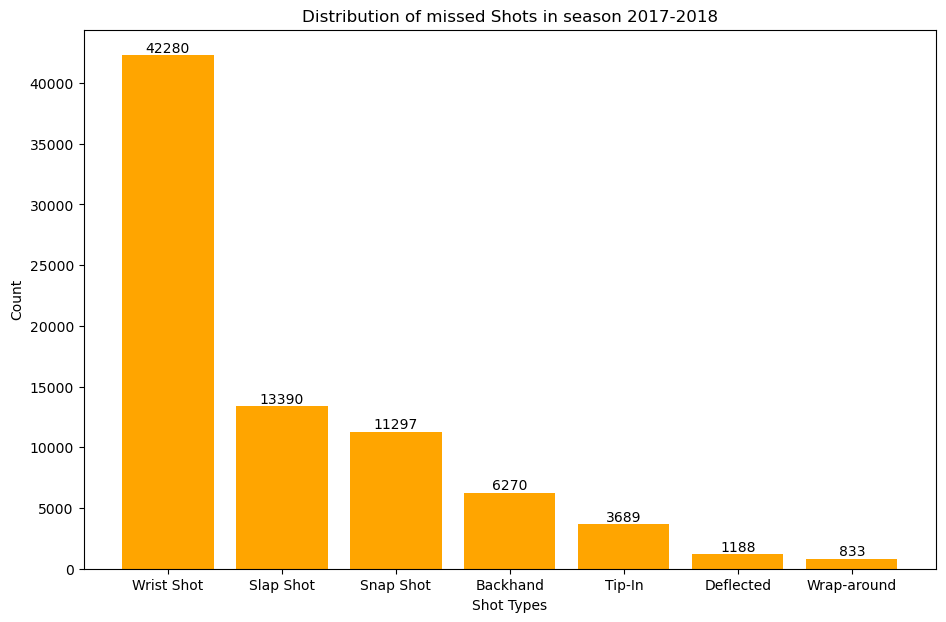
plt.figure(figsize=(11,7))bars2=plt.bar(goal_counts.index,goal_counts.values,color='green')forbarinbars2:yval=bar.get_height()plt.text(bar.get_x()+bar.get_width()/2,yval,round(yval,2),ha='center',va='bottom')plt.xlabel('Shot Types')plt.ylabel('Count')plt.title('Distribution of goals scored in season 2017-2018')plt.show()
This plot gives us the distribution of goals scored accross all the teams in season 2017-2018
We overlay the number of goals scored on top of number of shots missed.
plt.figure(figsize=(11,7))bars1=plt.bar(shot_counts.index,shot_counts.values,color='blue',label='Shots')bars2=plt.bar(goal_counts.index,goal_counts.values,color='red',label='Goals')plt.xlabel("Shot Types")plt.ylabel("Counts")plt.title("Distribution of Shot Types and Goals across Teams in season 2017-2018")plt.legend()plt.show()
To answer which type of shot is the most dangerous we use goals to shot ratio.
goal_to_shot_ratio=goal_counts/shot_countsplt.figure(figsize=(11,7))sorted_goal_to_shot_ratio=goal_to_shot_ratio.sort_values(ascending=False)plt.bar(sorted_goal_to_shot_ratio.index,sorted_goal_to_shot_ratio.values,color='purple')plt.xlabel('Shot Types')plt.ylabel('Goal-to-Shot Ratio')plt.title('Goal-to-Shot Ratio for Each Shot Type in season 2017-2018')
As shown in the bar graph the most dangerous type of shot is the “Deflected” shot type.
4.2 relationship between the distance a shot was taken and the chance it was a goal
This snippit of code displays the filtering, processing, and binning shot data.
To kick things off, we begin by filtering our dataset based on seasons. The filter_by_season function allows us to segment the data into three distinct seasons: 2018-2019, 2019-2020, and 2020-2021. Next, we explore the absolute values of the x-coordinates of shots. The abs function is applied to each season’s DataFrame, creating a new column named “x_values” representing the absolute x-coordinate. Taking our analysis a step further, we calculate the distance from each shot to the goal using the Euclidean distance formula. The process_season_df function enriches our DataFrame with a new column, “Distance_from_shot_to_goal.” To facilitate a comprehensive analysis, we categorize the distances into bins. The process_distance_bins function bins the distances into 10-yard intervals, creating a new column named “distance_bin.”
Our processed dataframe would look like this.
At the heart of our analysis is the calculate_percentage_goals function.
We start by isolating shot and goal events from our processed DataFrame (df_20_21_processed). The code filters the DataFrame to include only ‘SHOT’ and ‘GOAL’ events. The data is grouped based on the specified group_column, which in this case is ‘distance_bin.’ This groups shots and goals into bins representing different shot distances. We calculate the percentage of goals for each distance bin by dividing the number of goals by the number of shots and multiplying by 100. Now, let’s apply this function to our processed data for the 2020-2021 season and analyze goal percentages based on shot distances. All these steps are done for the dataframe df_18_19_processed and df_19_20_processed.
We plot the graph for all the season of 2020-2021, 2019-2020, 2018-2019.
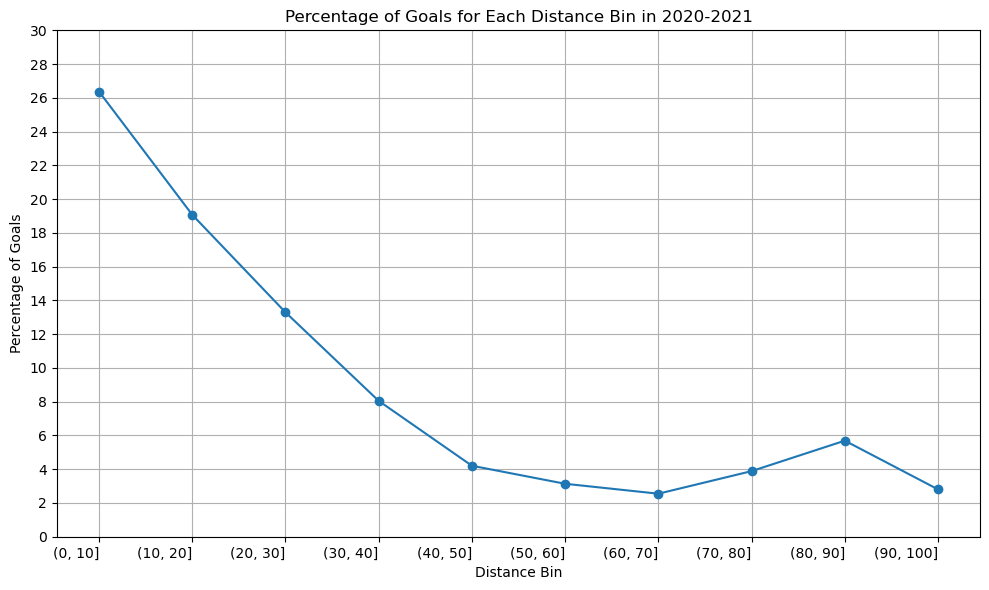
Season 2020-2021
distance_bins=['(0, 10]','(10, 20]','(20, 30]','(30, 40]','(40, 50]','(50, 60]','(60, 70]','(70, 80]','(80, 90]','(90, 100]']percentage_goal_values=[26.375148,19.075207,13.296433,8.048613,4.205128,3.136553,2.548387,3.886398,5.689900,2.803738]plt.figure(figsize=(10,6))plt.plot(distance_bins,percentage_goal_values,marker='o',linestyle='-')plt.xlabel('Distance Bin')plt.ylabel('Percentage of Goals')plt.title('Percentage of Goals for Each Distance Bin in 2020-2021')plt.xticks(rotation=0,ha='right')plt.yticks([0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30])plt.tight_layout()plt.grid()plt.show()
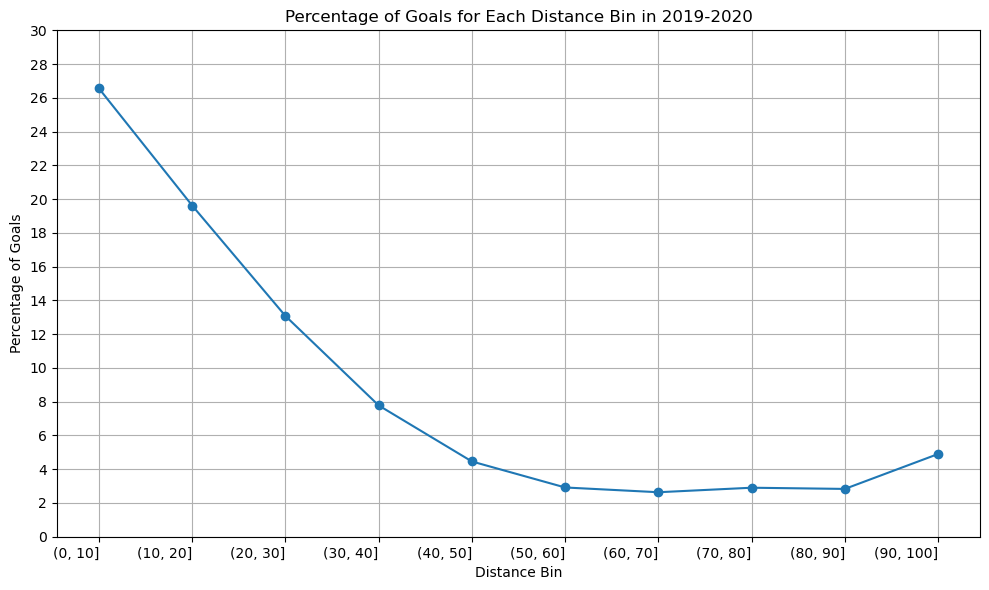
Season 2019-2020
distance_bins=['(0, 10]','(10, 20]','(20, 30]','(30, 40]','(40, 50]','(50, 60]','(60, 70]','(70, 80]','(80, 90]','(90, 100]']percentage_goal_values=[26.555337,19.617940,13.077823,7.778287,4.458217,2.917599,2.635838,2.902903,2.832031,4.899135]plt.figure(figsize=(10,6))plt.plot(distance_bins,percentage_goal_values,marker='o',linestyle='-')plt.xlabel('Distance Bin')plt.ylabel('Percentage of Goals')plt.title('Percentage of Goals for Each Distance Bin in 2019-2020')plt.xticks(rotation=0,ha='right')plt.yticks([0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30])plt.tight_layout()plt.grid()plt.show()
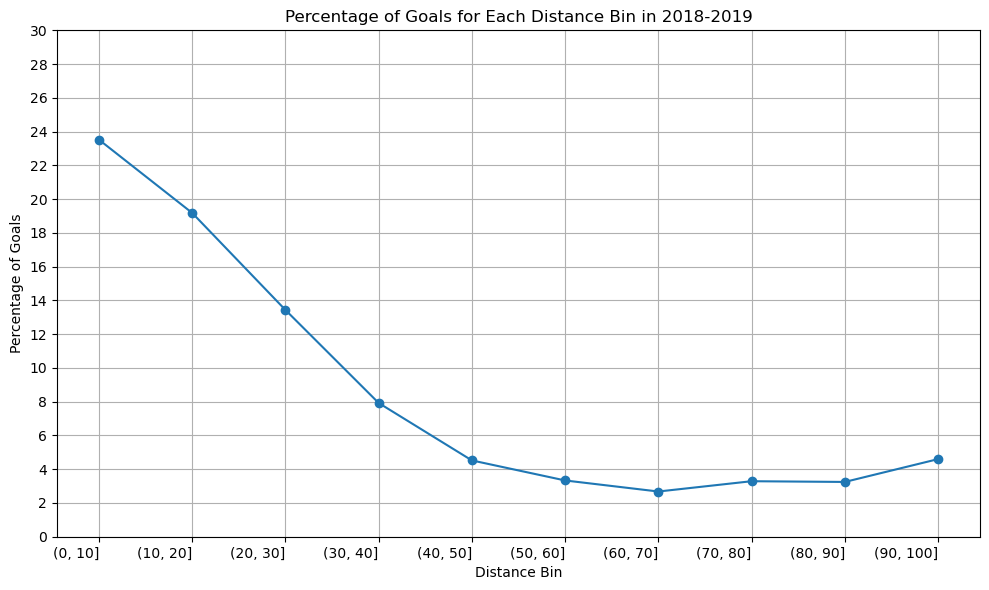
Season 2018-2019
distance_bins=['(0, 10]','(10, 20]','(20, 30]','(30, 40]','(40, 50]','(50, 60]','(60, 70]','(70, 80]','(80, 90]','(90, 100]']percentage_goal_values=[23.519953,19.180947,13.433584,7.922977,4.520010,3.333050,2.677974,3.288364,3.245090,4.597701]plt.figure(figsize=(10,6))plt.plot(distance_bins,percentage_goal_values,marker='o',linestyle='-')plt.xlabel('Distance Bin')plt.ylabel('Percentage of Goals')plt.title('Percentage of Goals for Each Distance Bin in 2018-2019')plt.xticks(rotation=0,ha='right')plt.yticks([0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30])plt.tight_layout()plt.grid()plt.show()
The graph’s structure is unchanged, as you can see, although the percentage of goals scored between [80-90] yards increased somewhat in the 2020–2021 season compared to the previous two. Since we have information about the three seasons, there won’t be any appreciable variations in the relationship between shot distance and shot taken. Since play styles may change over time and rules and developments may have an impact on the relationship between the distance and the type of shot taken, perhaps there would be a significant difference if we had more than 50 years.
A line graph is an excellent choice when dealing with data that has a sense of continuity or order, such as distance bins. In our case, the distance bins form a sequential and ordered set. The primary objective is to showcase trends in goal percentages as distances increase. A line graph, with distance bins on the x-axis and corresponding goal percentages on the y-axis, naturally emphasizes trends and patterns. The line connecting data points visually signifies the connection and progression from one distance bin to the next. This is essential for highlighting any smooth transitions or abrupt changes in goal percentages. In conclusion, the choice of a line graph is justified by its ability to effectively convey trends and variations in goal percentages across different shot distances.
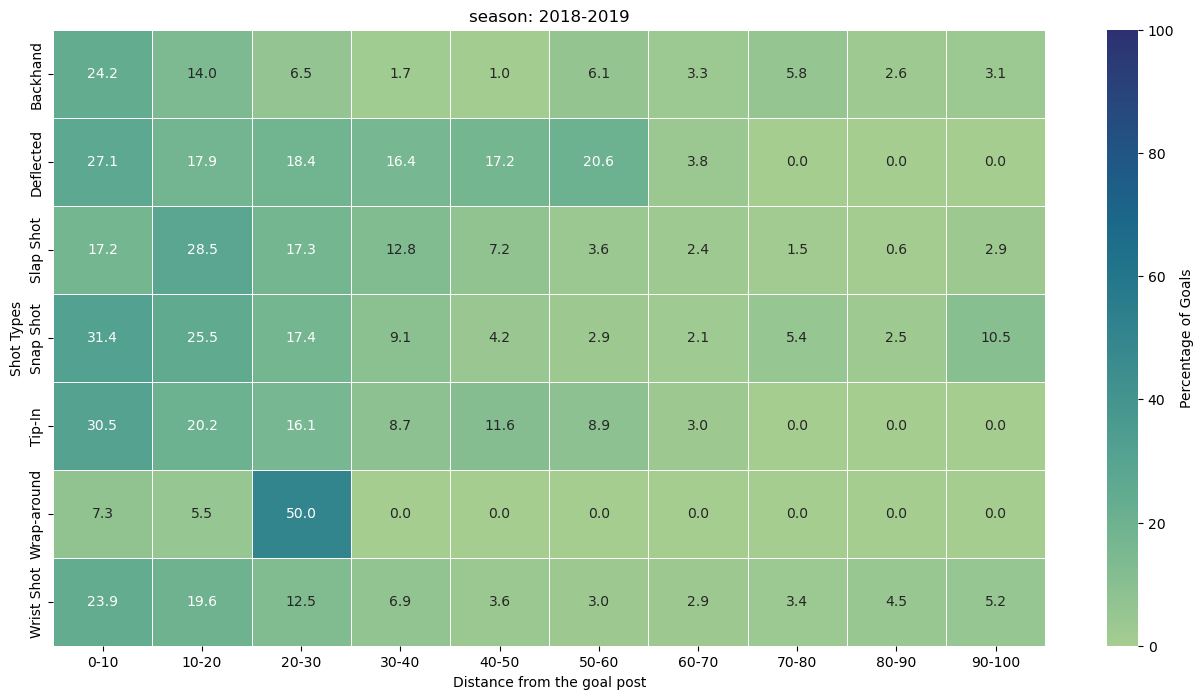
Question 3. shows the goal percentage (# goals / # shots) as a function of both distance from the net, and the category of shot types
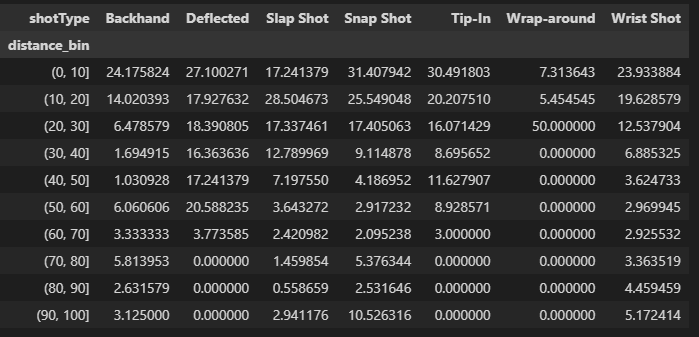
The heart of our analysis lies in two key variables: shot_counts and goal_counts. Let’s delve into the code to understand how these metrics are derived. We begin by isolating shot and goal events from our 2018-2019 season DataFrame (df_18_19). The groupby function is then used to group data by both ‘distance_bin’ and ‘shotType.’ The size function counts the occurrences of each combination of ‘distance_bin’ and ‘shotType,’ resulting in a DataFrame where rows represent distance bins, columns represent shot types, and each cell represents the count of shots or goals. The unstack function is applied to reshape the grouped data, making it more readable. The resulting DataFrame, shot_counts and goal_counts, has distance bins as rows, shot types as columns, and counts as cell values. The percentage of goals is calculated by dividing the ‘goal_counts’ by ‘shot_counts’ and multiplying by 100. This operation results in a DataFrame where each cell represents the percentage of goals for a specific shot type and distance bin.
The dataframe would look like this.
Using this information we plot the heatmap for the season 2018-2019.
plt.figure(figsize=(16,8))heatmap=sns.heatmap(percentage_goals.T,annot=True,fmt=".1f",linewidth=.5,cmap="crest",vmin=0,vmax=100,cbar_kws={'label':'Percentage of Goals'})plt.xlabel('Distance from the goal post')plt.ylabel('Shot Types')plt.title('season: 2018-2019')new_tick_labels=['{}-{}'.format(b.left,b.right)forbinpercentage_goals.index.categories]heatmap.set_xticklabels(new_tick_labels,rotation=0)plt.show()
Observation from the heatmap.
(0, 10] Distance Bin:
Snap Shots (31.41%): Snap shots dominate in this close-range distance bin, showcasing their effectiveness in quick, close-quarter situations.
(10, 20] Distance Bin:
Slap Shots (28.50%): Slap shots take the lead at a slightly greater distance, suggesting their potency in mid-range scenarios.
Snap Shots (25.55%): Snap shots continue to maintain a high success rate in this range.
(20, 30] Distance Bin:
Wrap-around (50.00%): Wrap-around shots emerge as highly effective in the mid-range, indicating their success in situations closer to the goal.
(30, 40] Distance Bin:
Deflected (16.36%): Deflected shots showcase reasonable success in this distance bin, providing a tactical option for goal-scoring opportunities.
(40, 50] Distance Bin:
Deflected (17.24%): Deflected shots maintain effectiveness, suggesting their utility even at greater distances.
Backhand (11.63%): Backhand shots also demonstrate noteworthy success.
(50, 60] Distance Bin:
Deflected (20.59%): Deflected shots continue to be a formidable option.
Backhand (8.93%): Backhand shots maintain their presence as a strategic choice.
(60, 70] Distance Bin:
Deflected (3.77%): Deflected shots see a slight decrease in success.
Backhand (3.33%): Backhand shots remain a viable, albeit less common, choice.
(70, 80] Distance Bin:
Backhand (5.81%): Backhand shots regain prominence at this longer distance, suggesting their potential in varied scenarios.
(80, 90] Distance Bin:
Backhand (4.46%): Backhand shots continue to exhibit a presence, albeit with a lower success rate.
(90, 100] Distance Bin:
Snap Shots (10.53%): Surprisingly, snap shots regain prominence in the longest distance bin, showcasing their adaptability even at a distance from the goal.
This analysis provides helpful insights on the efficacy of various shots at various distances, even if the success of a shot type depends on a variety of factors, including player skill, defensive methods, and goalkeeper proficiency. This knowledge can be used by coaches and players to modify their tactics and emphasise the significance of selecting the appropriate shot type in particular game situations.
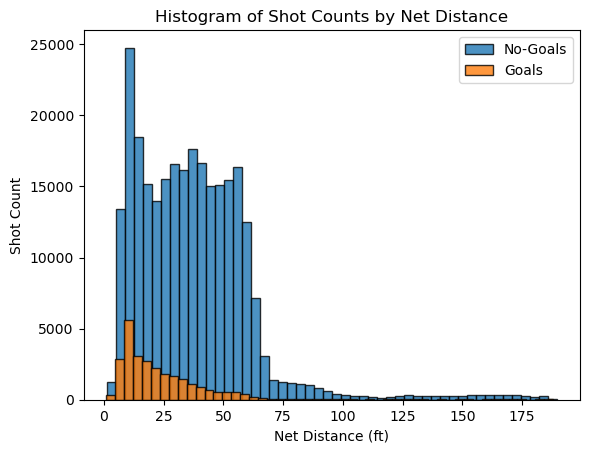
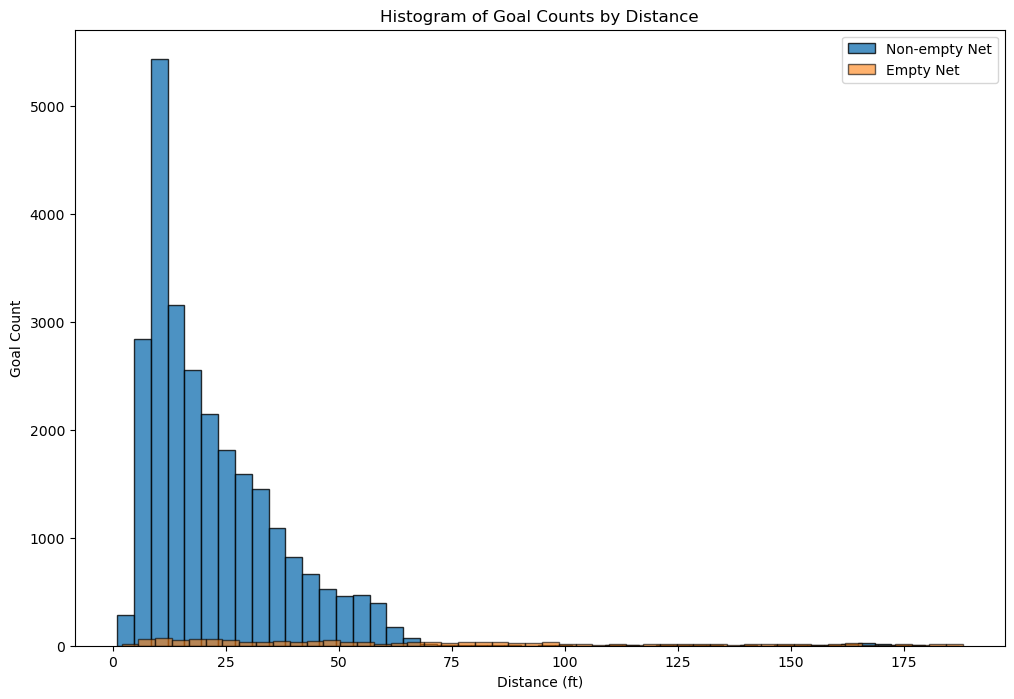 The majority of goals are scored from a close distance. There are very few goals scored on an empty net. They are spread out over a range of distances, including some from very long ranges. The non-empty net goals are rarely scored from distances beyond 75 feet, underscoring the difficulty of scoring long-range goals with the presence of a goalie.
The majority of goals are scored from a close distance. There are very few goals scored on an empty net. They are spread out over a range of distances, including some from very long ranges. The non-empty net goals are rarely scored from distances beyond 75 feet, underscoring the difficulty of scoring long-range goals with the presence of a goalie.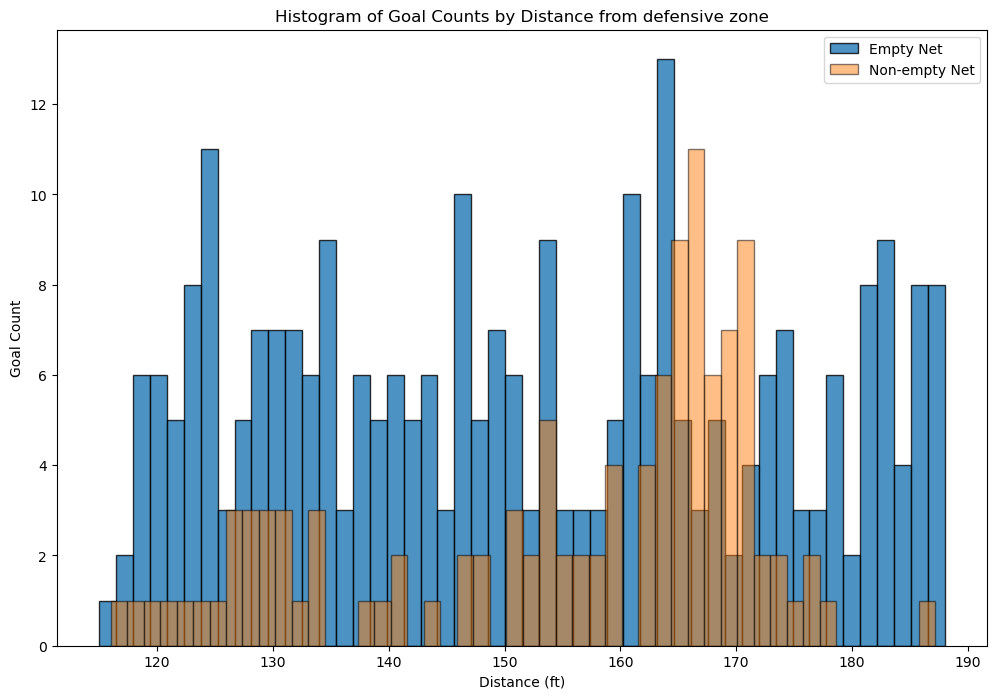










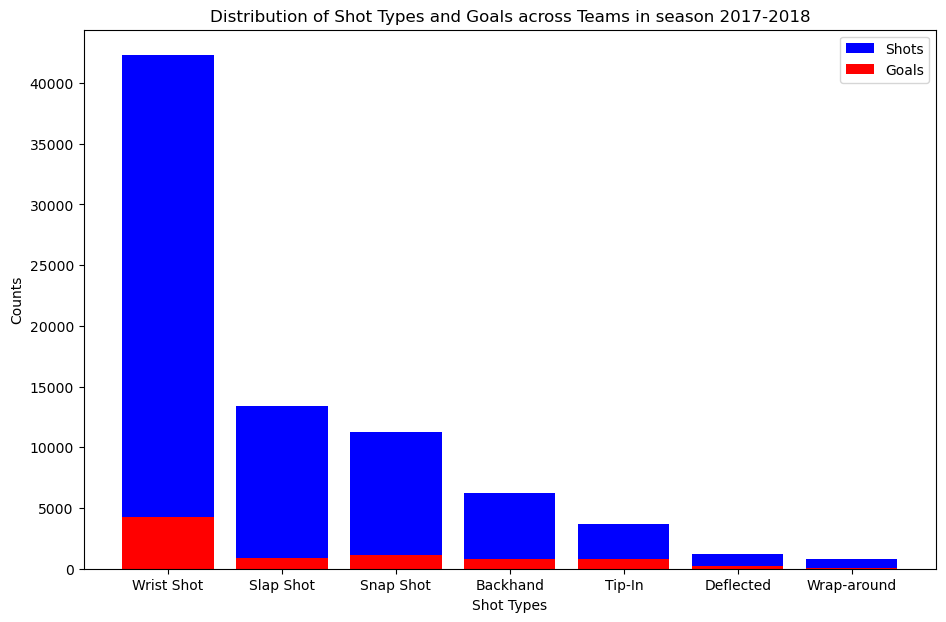 To answer which type of shot is the most dangerous we use goals to shot ratio.
To answer which type of shot is the most dangerous we use goals to shot ratio.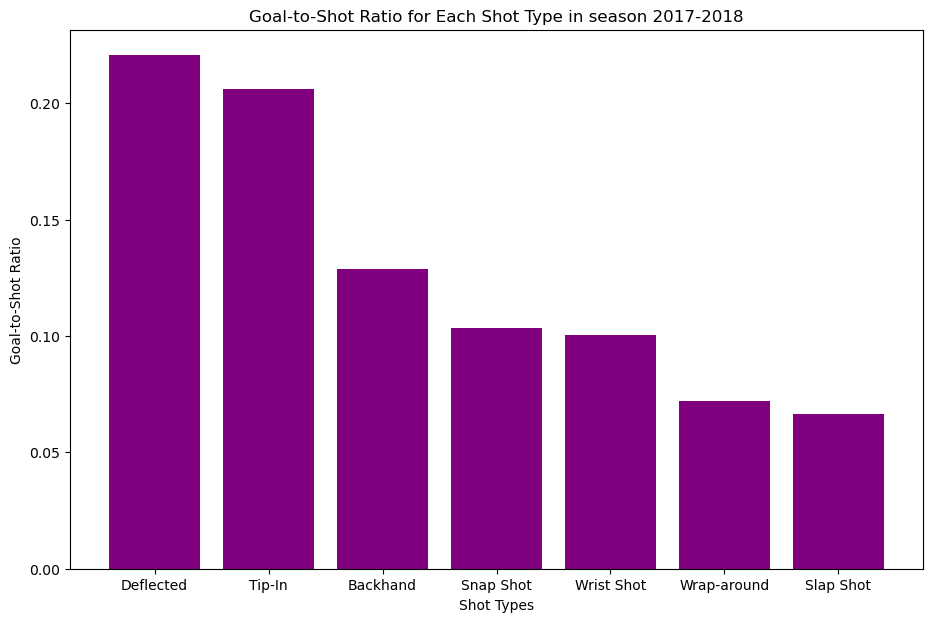 As shown in the bar graph the most dangerous type of shot is the “Deflected” shot type.
As shown in the bar graph the most dangerous type of shot is the “Deflected” shot type.